
Guest post by Tameka Sama, Gevork Harootunian, George Runger of the Center for Health Information & Research, Arizona State University
Probabilistic, fuzzy and deterministic are generally not words used to define clear operations. But in the world of data linking algorithms, these terms go hand-in-hand.
The health sector fully understands how we ended up with health data in so many formats, from clinical to claims data. The question became how do we combine information from various formats and types of health data into one format that we can use in studies or other aspects of health care?
 The Arizona State University Center for Health Information and Research (CHiR) works in the health information technology sector, and routinely confronts that very question. CHiR patterned itself after the “community health data system model” and developed a centralized repository of health information on Arizonans. Data came from providers, insurers and government agencies and included claims, lab results, vital records, hospital discharge data, and other health information. A key aspect of the model’s success was keeping the process simple for those sharing their data with us voluntarily. Therefore, we accepted data from any platform/software. The challenge was combining all of this data, which did not contain mutually unique identifiers. Even the existing identifiers varied in quality, accuracy and availability.
The Arizona State University Center for Health Information and Research (CHiR) works in the health information technology sector, and routinely confronts that very question. CHiR patterned itself after the “community health data system model” and developed a centralized repository of health information on Arizonans. Data came from providers, insurers and government agencies and included claims, lab results, vital records, hospital discharge data, and other health information. A key aspect of the model’s success was keeping the process simple for those sharing their data with us voluntarily. Therefore, we accepted data from any platform/software. The challenge was combining all of this data, which did not contain mutually unique identifiers. Even the existing identifiers varied in quality, accuracy and availability.
CHiR implemented processes for loading, scrubbing, validating, standardizing, and linking new data to existing data. Had each data source contained reliable unique identifiers, our matching operation would have been trivial. Rather, a customized matching algorithm was developed to probabilistically link patients across the many data sources where unique patient identifiers were unavailable, as well as match claims & providers across systems. We have transitioned from the community health data system model into other types of centralized repositories, but we have continued to refine the algorithm.
Today, the linking process goes through probabilistic, fuzzy and deterministic algorithms and uses a number of demographic data elements for matching, depending on availability.
The first step in the probabilistic matching assigns a block variable to each record. Blocking focuses the scope of record pairs to examine by using reliable and commonly available data that has a low likelihood of error. Blocking partitions the records into mutually exclusive and exhaustive subsets. The matching process searches for matches only within a subset.
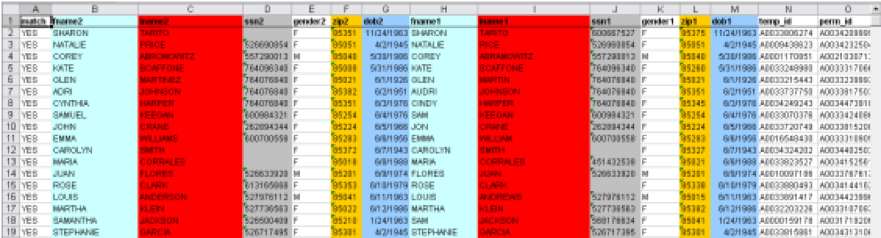
The next step assigns numeric scores called weights to individual data columns. Weights are determined both probabilistically and through prior knowledge of the quality of variables or features of the matching population. The matching process produces composite difference scores through comparison of individual data elements. Names go through additional calculations, including phonetic algorithms. Some data elements are weighted more because they are more critical to the match or more reliable than others are. A threshold value is adjusted to reflect the importance of the data element to its domain and to the overall comparison.
Deterministic rules are set in the algorithm to filter the records. These rules are based on previous experience and have been heavily validated. Finally, a record is classified as a match if the composite weight is above a cutoff value. Records with a composite weight below the cutoff value are classified as “nomatch”. A record that falls between the two cutoffs is classified as a ”manual match”. The manual match records are exported for a trained programmer to make an assessment and determination regarding matching.
CHiR’s data linking capability has been instrumental in its success not only producing robust data for health studies, but also retaining data sharing partners.
CHiR has been a community resource and partner for organizations and individuals seeking comprehensive health information, data analytics and reporting for public, private and research uses for nearly 20 years. CHiR securely collects, stores, and analyzes identifiable health and social determinants data from a variety of voluntary and publicly available sources. All CHiR data are linkable, creating one of the most complete and accurate longitudinal profiles of individuals and populations over time and across providers and insurers in Arizona. Learn more at chs.asu.edu/chir.