
Guest post by Mónica Arrúe and Gorka Epelde from Vicomtech
In the context of the MIDAS project several datasets from different data sources will be processed. Each of these datasets will have a different structure and the quality of the data may vary from one dataset to another. Because of this, a standard data integration methodology has been defined for all the datasets to be used in MIDAS project. The main purpose of this approach is to upload pre-processed and high-quality data to the MIDAS repository, which is essential within a data-driven decision-making context like that of MIDAS project. The methodology for data integration is described hereafter.
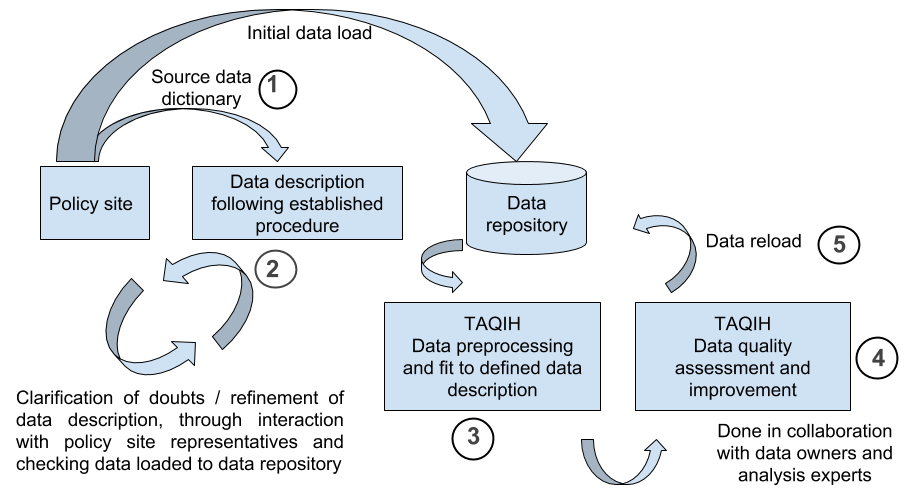
The first step in the data ingestion methodology is that policy site responsible representatives share an initial data dictionary and the source dataset for an initial data load (step 1). In order to have this information described in a standard way for all datasets (to aid data analysts and data visualisation experts work), a document has been created describing the procedure to be followed to describe the datasets and has been applied to each of the datasets (step 2). The purpose of the document is to homogenise the way in which datasets provided by healthcare institutions and other data sources (such as governmental open data) are described to other partners, especially technical partners with limited clinical knowledge. The dataset description document has the following sections:
- Dataset description
In this section a short description of the contents of the dataset including its initial purpose and context are provided. It also contains information about the structure of the dataset (i.e. tables and the relationship between them), general issues regarding data quality and a list of the used standards, if any.
- File and “sub-file” description
This section contains a description for each of the dataset tables and a list of the variables contained in each of them. Besides this, if any pre-processing of the data has been performed is should be indicated here.
- Variable/column description
For each of the variables the following information is provided:
- Name of the variable
- Short description of the variable
- Type of data values (i.e. integer, float, boolean…)
- Units of the data
- Format of the variable / Link to categories table / Specific Coding Standard
- Pre-processing description
- Link if it’s a variable to link to another table
In this phase it’s necessary to work together with the policy site representatives and check the initially uploaded data from the data repositories with the aim of clarifying any queries with the dataset.
Once the data is uploaded to the repository and the dataset description is made, data pre-processing is carried out using the TAQIH (Tabular data Quality assessment and Improvement, in the context of Health data) tool (step 3). The main objective of this step is to improve the data quality and to fit it to the defined data description. The next step is to carry out a data quality assessment and to improve it using the TAQIH tool (step 4). This step is done in collaboration with data owners and analysis experts. Finally, this pre-processed and high-quality data is reloaded to the data repository (step 5).
In addition to the dataset description carried out in step 2 of the data integration process, these datasets are going to be described with the ISAACUS GSIM-based metadata model developed in Finland. The objective of describing the MIDAS datasets according to this metadata model is to have all the datasets described by this standard and correctly labelled in order to make them computer processable and to facilitate the identification of harmonisable attributes and the subsequent harmonisation of the datasets. The ISAACUS web application has been translated to English as it was only in Finnish and dataset descriptions are being moved to this tool.